AstroLLaVA: towards the unification of astronomical data and natural language
Apr 11, 2025·,,,,,,, ,,·
0 min read
,,·
0 min read
Sharaf Zaman
Michael J. Smith
Pranav Khetarpal
Rishabh Chakrabarty
Michele Ginolfi
Marc Huertas-Company
Maja Jabłońska
Sandor Kruk
Matthieu Le Lain
Sergio José Rodríguez Méndez
Dimitrios Tanoglidis
Abstract
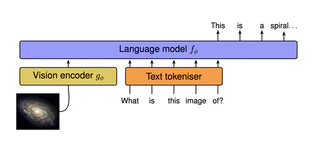
We present AstroLLaVA, a vision language model for astronomy that enables interaction with astronomical imagery through natural dialogue. By fine-tuning the LLaVA model on a diverse dataset of ~30k images with captions and question-answer pairs sourced from NASA’s Astronomy Picture of the Day, the European Southern Observatory, and the NASA/ESA Hubble Space Telescope, we create a model capable of answering open-ended questions about astronomical concepts depicted visually. Our two-stage fine-tuning process adapts the model to both image captioning and visual question answering in the astronomy domain.
Type
Publication
SCI-FM@ICLR 2025, arXiv:2504.08583

Authors
AI for astronomy & astrophysics
PhD student at IRISA, Université Bretagne Sud (expected 2026), and lecturer in computer science,
working on foundation models for astronomy and astrophysics, with a broader interest
in deep learning applied to scientific data.
Also contributing to the UniverseTBD collaboration on vision–language models for astronomy.